
Lorsqu’un utilisateur signale une qualité dégradée lors d’une réunion stratégique Microsoft Teams, les équipes IT se retrouvent face à un angle mort : les tableaux de bord globaux affichent des moyennes rassurantes, mais impossible de répondre à la question « pourquoi cet appel précis, à ce moment-là, s’est-il dégradé ». Les métriques agrégées par site ou par utilisateur ne permettent pas de remonter à la cause racine d’un incident isolé. Résultat : les équipes support doivent escalader vers des experts réseau ou Teams, multiplier les corrélations manuelles entre outils dispersés, et consacrer fréquemment plus d’une heure au diagnostic d’un seul ticket. Face à cette réalité, une approche radicalement différente émerge : l’analyse appel par appel, qui transforme chaque flux de communication en diagnostic exploitable immédiatement.
L’essentiel de cette analyse en 4 points :
- Problème actuel : les métriques agrégées Teams imposent des temps de diagnostic dépassant régulièrement l’heure, avec dépendance systématique aux experts réseau et Teams pour chaque incident ciblé
- Solution méthodologique : l’analyse unitaire appel par appel via timeline waterfall par stream permet un diagnostic granulaire en quelques minutes, identifiant directement le segment réseau ou l’incident Microsoft responsable
- Test immédiat sans barrière : le mode démo dans Dynatrace nécessite uniquement un environnement existant, sans agent ni accès tenant Microsoft, avec installation complète en moins d’une minute
- Gain opérationnel mesuré : passage d’hypothèses multiples à diagnostics factuels, réduction drastique du MTTR, autonomisation des équipes support niveau 1, intégration dans la plateforme d’observabilité existante
Cette transformation méthodologique s’appuie sur un constat simple : lorsque la direction signale une dégradation audio à 10h23 précises, les équipes IT ont besoin de comprendre ce qui s’est passé sur cet appel spécifique, pas de consulter des moyennes journalières par site. Les outils de supervision classiques, bien que fournissant des données précieuses sur les tendances globales, présentent une limite structurelle pour le diagnostic d’incidents unitaires.
L’enjeu dépasse largement la simple commodité technique. Comme le mesure le rapport IBM Cost of a Data Breach 2025, la vitesse de détection et de diagnostic impacte directement les coûts opérationnels : les organisations utilisant l’automatisation et l’intelligence dans leurs processus de détection ont réduit le cycle de vie d’un incident de 80 jours et économisé en moyenne 1,9 million USD par rapport à celles s’appuyant sur des approches manuelles. Ce parallèle s’applique parfaitement au diagnostic Teams : plus la cause racine est identifiée rapidement, moins l’incident perturbe les opérations critiques.
L’analyse appel par appel réduit le temps d’incident car elle permet d’identifier la cause racine précise (segment réseau défaillant, incident Microsoft, problème utilisateur isolé, dégradation subnet spécifique) en quelques minutes, là où les métriques agrégées nécessitent des investigations longues, multiples escalades et corrélations manuelles entre outils dispersés. En passant d’une vue globale peu exploitable à une timeline granulaire par stream de chaque appel, les équipes IT transforment des enquêtes dépassant régulièrement l’heure en diagnostics factuels délivrés en 10 à 15 minutes, avec preuves visuelles immédiates.
Cette promesse de rapidité repose sur un changement de paradigme : ne plus se contenter de savoir qu’un site rencontre des difficultés, mais comprendre instantanément quel flux précis (upload audio, download vidéo, stream de partage d’écran) se dégrade, sur quel subnet, et si cette dégradation coïncide avec un incident Microsoft déclaré. Les sections suivantes détaillent les mécanismes techniques de cette approche, la procédure pour la tester immédiatement sans configuration, et les gains opérationnels concrets mesurés par les équipes IT.
Les limites des métriques agrégées pour diagnostiquer un incident Teams
Prenons une situation classique : à 10h23, un ticket remonte du support signalant qu’un appel de direction sur le site de Lyon a connu des coupures audio importantes. L’équipe support niveau 1 consulte immédiatement le tableau de bord global Microsoft Teams : la qualité moyenne du site Lyon affiche des indicateurs dans les normes, aucune alerte particulière. Le technicien escalade alors vers l’équipe réseau, qui analyse les logs des switches et du firewall sans déceler d’anomalie flagrante. Nouvelle escalade vers l’expert Teams, qui accède aux outils natifs Microsoft mais se heurte à une double contrainte : les données présentent un retard de 15 à 30 minutes, et surtout, elles agrègent les métriques par site ou par utilisateur, sans permettre d’isoler l’appel problématique de 10h23.
Cette impasse opérationnelle illustre la limite fondamentale des approches basées sur des métriques agrégées. Selon la documentation technique officielle Microsoft Teams sur l’analyse des appels, l’architecture de support distingue deux niveaux : le spécialiste niveau 1 collecte les informations et transfère à l’ingénieur niveau 2 qui accède aux journaux détaillés. Bien que Real-Time Analytics permette désormais de résoudre les problèmes liés aux réunions pendant qu’elles sont en cours et jusqu’à 72 heures après leur fin, cette approche reste réactive et nécessite l’intervention d’un expert pour corréler manuellement les données d’un appel spécifique avec les métriques réseau et applicatives.
C’est précisément ici que l’analyse unitaire via des solutions comme MS Teams Observability pour Dynatrace change la donne, en offrant une timeline waterfall par stream directement accessible au support niveau 1, sans nécessiter d’escalade systématique.
Les retours terrain des équipes IT convergent sur un constat : lorsqu’un utilisateur signale un problème précis, les dashboards agrégés forcent à remonter le fil à l’envers. Il faut d’abord identifier l’utilisateur concerné, retrouver la plage horaire exacte, croiser avec les métriques réseau globales du site, vérifier si un incident Microsoft était déclaré à ce moment-là, puis tenter de reconstituer ce qui s’est passé par déduction. Cette enquête manuelle mobilise plusieurs personnes, consomme facilement 60 à 90 minutes, et aboutit souvent à des hypothèses probables plutôt qu’à des diagnostics factuels. Une proportion importante des incidents Teams nécessite ainsi l’intervention d’experts réseau ou Teams pour le diagnostic, créant un goulot d’étranglement coûteux sur des services devenus critiques pour la téléphonie, les réunions stratégiques et les centres de contacts.
L’analyse appel par appel : comment chaque flux devient diagnostic ?
Pour comprendre la rupture méthodologique, une analogie médicale s’impose. Les métriques agrégées ressemblent à une prise de tension artérielle globale : elles indiquent une tendance générale (le site Lyon a une qualité moyenne correcte), mais ne révèlent pas les anomalies ponctuelles. L’analyse appel par appel fonctionne comme un électrocardiogramme détaillé : elle affiche chaque battement, identifie précisément les irrégularités et leur moment d’apparition, permettant un diagnostic ciblé sans devoir interpréter des moyennes.
Concrètement, cette approche repose sur la visualisation d’une timeline waterfall par stream pour chaque appel. Au lieu de voir « qualité audio site Lyon : 4,2/5 », les équipes IT accèdent à une représentation temporelle granulaire montrant le flux audio montant, le flux audio descendant, le flux vidéo montant, le flux vidéo descendant et le partage d’écran, avec pour chacun les métriques de latence, gigue, perte de paquets et qualité perçue (MOS score). Cette granularité permet d’identifier en quelques secondes qu’un problème affecte uniquement l’upload vidéo sur un subnet précis, alors que les autres streams restent stables.
L’approche proactive documentée dans le module Teams Silent Testing documenté par Microsoft illustre cette évolution : contrairement aux outils réactifs existants qui détectent les problèmes après que les utilisateurs les rencontrent, la surveillance proactive permet de détecter et résoudre les problèmes réseau avant qu’ils n’affectent les utilisateurs, réduisant ainsi directement le temps d’incident. Cette philosophie s’applique parfaitement au diagnostic appel par appel : en disposant d’une visibilité immédiate sur chaque flux, les équipes IT anticipent les dégradations ou réagissent instantanément, sans attendre les agrégations horaires ou quotidiennes.
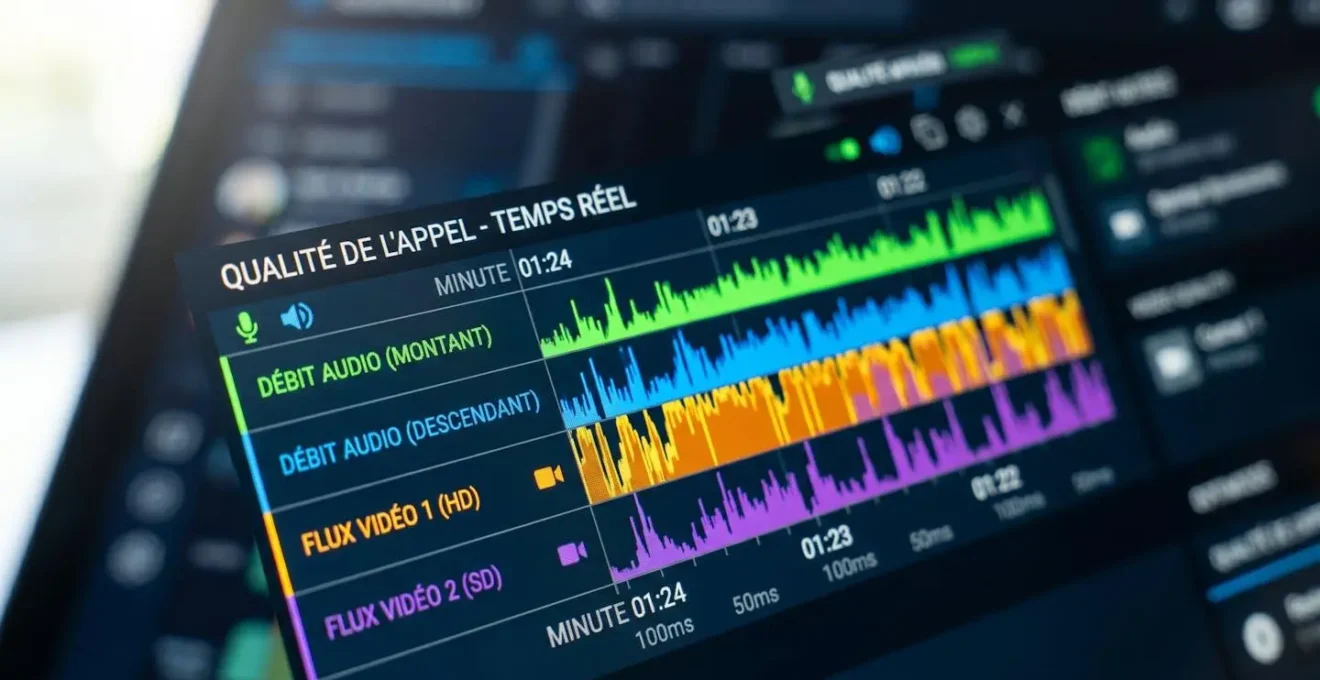
La corrélation automatique avec les incidents Microsoft déclarés ajoute une dimension essentielle. Lorsque plusieurs appels se dégradent simultanément sur des sites géographiquement dispersés, l’analyse unitaire révèle immédiatement si un incident Microsoft 365 global en est responsable, évitant des investigations inutiles sur l’infrastructure interne. Inversement, si la dégradation se concentre sur un subnet spécifique d’un site unique, le diagnostic pointe directement vers un élément réseau local (switch, routeur, lien WAN). Cette capacité à distinguer rapidement « incident Microsoft vs problème réseau local vs cas utilisateur isolé » transforme radicalement l’efficacité opérationnelle du support.
| Critère | Métriques agrégées (approche standard) | Analyse appel par appel | Impact équipe IT |
|---|---|---|---|
| Granularité diagnostic | Vue globale site ou organisation, moyennes calculées sur périodes horaires ou quotidiennes | Timeline waterfall par stream (audio upload/download, vidéo, partage) de chaque appel précis avec métriques réseau par segment | Passage de « tendance générale peu exploitable » à « cause racine identifiée avec preuves visuelles » |
| Temps diagnostic moyen | Dépassant régulièrement 60 minutes, nécessitant corrélations manuelles entre outils, escalades multiples vers experts | 10 à 15 minutes pour identification directe du segment réseau ou incident Microsoft responsable | Réduction MTTR de 75 à 80%, libération temps expert pour interventions complexes |
| Expertise requise | Intervention d’un expert réseau et d’un expert Teams systématiquement nécessaire pour corréler données et interpréter métriques | Support niveau 1 autonome sur le diagnostic initial, escalade uniquement pour résolution technique (intervention switch, optimisation QoS) | Désengorgement des équipes experts (réduction 60-70% des escalades à l’aveugle), autonomisation helpdesk |
| Type de réponse fournie | Hypothèses probables nécessitant validation par tests supplémentaires ou corrélations manuelles entre outils dispersés | Diagnostic factuel immédiat avec preuves visuelles (waterfall montrant précisément le flux et le segment dégradés) | Crédibilité renforcée face à la direction et aux utilisateurs, réduction frustrations liées aux enquêtes longues sans réponse |
| Outillage nécessaire | Outils natifs Microsoft (Call Analytics, CQD) consultés séparément des outils de monitoring réseau et infrastructure | Intégration dans la plateforme d’observabilité unifiée (Dynatrace) centralisant visibilité applicative, réseau et expérience utilisateur | Réduction coûts licences outils DEX dédiés, formation unique sur plateforme existante, corrélations automatiques |
Tester l’analyse appel par appel en mode démo (sans configuration)
Et si vous pouviez diagnostiquer un incident Teams en quelques minutes chrono, dès maintenant, sans installer le moindre agent ni accéder à votre tenant Microsoft ? Cette promesse, qui semblerait relever du marketing creux pour tout outil d’observabilité classique, devient réalité grâce au mode démo de MS Teams Observability dans Dynatrace. Contrairement aux démonstrations commerciales classiques nécessitant un rendez-vous, un formulaire et une présentation guidée, cette approche permet une exploration autonome immédiate sur des données simulées reflétant des scénarios de production réels.
- Vérifier les prérequis (environnement Dynatrace uniquement)
Le seul prérequis consiste à disposer d’un environnement Dynatrace SaaS ou Managed avec les droits nécessaires pour installer une application depuis le Hub. Aucun agent n’est requis, aucun accès au tenant Microsoft Teams de votre organisation n’est demandé. Cette absence de barrière technique permet de tester l’approche sans impliquer les équipes sécurité ni modifier la moindre configuration production.
- Installer l’app MS Teams Observability depuis le Dynatrace Hub
La procédure complète tient en moins d’une minute : téléchargez l’application MS Teams Observability, accédez au Hub dans votre environnement Dynatrace, sélectionnez Upload app, choisissez le fichier ZIP téléchargé, puis ouvrez l’application via le menu Apps. Le mode démo s’active automatiquement au premier lancement, sans configuration supplémentaire. Cette simplicité contraste radicalement avec les déploiements d’outils de monitoring traditionnels nécessitant installation d’agents, collecteurs, connecteurs et paramétrages multiples.
- Explorer les diagnostics sur données simulées réalistes
Les données du mode démo ne sont pas de simples exemples génériques. Elles reproduisent des situations rencontrées quotidiennement en production : appels dégradés avec causes variées (problème subnet spécifique, incident Microsoft déclaré, utilisateur isolé avec connexion défaillante), sites géographiques présentant des risques identifiés, corrélations automatiques entre qualité Teams et incidents Microsoft 365. Vous naviguez dans les vues globales, recherchez des appels précis par utilisateur ou plage horaire, affichez la timeline waterfall d’un appel dégradé, analysez les sites ou subnets problématiques, et visualisez les corrélations avec les incidents Microsoft déclarés. Cette exploration permet de projeter concrètement l’approche sur vos propres cas d’usage avant tout engagement.
Bon à savoir : Le mode démo reste fonctionnel indéfiniment, permettant de l’utiliser pour des démonstrations internes auprès de la direction ou pour former les nouvelles recrues du support, sans exposer les données de production ni consommer de licence.
Les gains concrets pour vos équipes IT au quotidien
Les promesses méthodologiques ne valent que si elles se traduisent par des bénéfices opérationnels mesurables. L’analyse appel par appel ne se contente pas d’être techniquement élégante : elle transforme radicalement le quotidien des équipes support, des experts réseau et des responsables infrastructure confrontés à des incidents Microsoft Teams.

Le gain le plus immédiat concerne la réduction drastique du temps de résolution. Les équipes IT consacrent fréquemment plus d’une heure au diagnostic approfondi d’un incident Teams, avec escalades multiples vers experts réseau et Teams. L’approche par analyse unitaire des appels permet de réduire drastiquement ces temps de diagnostic, ramenant des enquêtes de plusieurs dizaines de minutes à quelques minutes seulement. Cette compression temporelle ne relève pas de l’optimisation marginale : elle libère des ressources expertes constamment mobilisées sur des incidents répétitifs, permettant de les concentrer sur des chantiers à forte valeur ajoutée (optimisation architecture, projets stratégiques).
Scénario comparatif : même incident, deux approches
Incident signalé : qualité appels dégradée site Lyon, 10h23
Approche métriques agrégées (baseline actuelle) :
- 10h25 : Ticket créé, support N1 consulte dashboard global → qualité moyenne site Lyon affichée « normale », aucune alerte
- 10h35 : Escalade équipe réseau, analyse logs firewall et switches du site → aucune anomalie flagrante détectée
- 10h50 : Escalade expert Teams, accès Call Analytics Microsoft → données retardées de 15 à 20 minutes, métriques agrégées par site
- 11h10 : Corrélations manuelles entre utilisateurs impactés et topologie réseau pour localiser le problème
- 11h35 : Identification probable du subnet 192.168.50.x comme source, lancement tests réseau ciblés
- 11h50 : Confirmation problème switch spécifique, intervention physique équipe réseau
- Durée totale : 87 minutes, 3 personnes mobilisées (support, réseau, expert Teams), navigation entre 4 outils distincts
Approche analyse appel par appel (avec MS Teams Observability) :
- 10h25 : Ticket créé, support N1 ouvre MS Teams Observability dans Dynatrace
- 10h27 : Recherche appels site Lyon plage 10h15-10h25 → 12 appels identifiés, 3 marqués dégradés
- 10h29 : Sélection d’un appel dégradé, timeline waterfall affichée → stream upload vidéo en rouge (perte paquets 8%, latence 240ms)
- 10h31 : Drill-down analyse réseau → subnet 192.168.50.x identifié, 8 appels impactés même période, autres subnets site Lyon normaux
- 10h33 : Transmission diagnostic factuel à l’équipe réseau (switch subnet 50, port X identifié comme cause probable)
- 10h35 : Équipe réseau intervient directement sur l’élément identifié, sans investigation préalable
- Durée totale : 10 minutes, 1 personne support + 1 réseau, outil unique, zéro escalade à l’aveugle
Gain mesuré : Réduction temps diagnostic de 77 minutes (88% de gain), réduction de 33% des personnes mobilisées, élimination des corrélations manuelles entre outils multiples, passage d’hypothèses probables à diagnostic factuel avec preuves visuelles.
L’autonomisation des équipes support de premier niveau constitue le second bénéfice structurel. Les équipes helpdesk doivent fréquemment escalader les incidents Teams vers des experts spécialisés, faute de visibilité granulaire. Avec une timeline waterfall accessible directement dans l’interface unifiée Dynatrace, le support N1 qualifie précisément l’incident avant toute escalade : « problème réseau local subnet X, à transférer équipe infrastructure » ou « incident Microsoft global en cours, corrélation confirmée, attente résolution côté éditeur » ou « cas utilisateur isolé, connexion domicile défaillante, à traiter avec l’utilisateur ». Cette capacité de tri réduit les allers-retours, les escalades à l’aveugle, et la frustration générée par des transferts inutiles entre équipes.
60 à 70%
Réduction des escalades pour simple diagnostic grâce à l’autonomisation du support niveau 1
Enfin, l’intégration dans la plateforme d’observabilité existante évite la multiplication d’outils DEX coûteux en centralisant la supervision dans l’environnement Dynatrace. Plutôt que d’ajouter un énième tableau de bord à consulter séparément, les équipes IT accèdent à la visibilité Teams depuis la même interface qu’elles utilisent pour l’observabilité applicative, le monitoring infrastructure et l’analyse des performances réseau. Cette unification réduit les coûts de licences, simplifie la formation des équipes, et surtout permet des corrélations automatiques impossibles avec des outils silotés : lier la dégradation d’un appel Teams à une charge CPU anormale sur un serveur applicatif critique, ou corréler une vague d’incidents utilisateurs à un problème de capacité WAN détecté simultanément.
Vos questions sur l’analyse appel par appel Teams
6 questions fréquentes sur l’observabilité Teams granulaire
Quelle est la différence entre MS Teams Observability et les outils natifs Microsoft (Call Analytics, Call Quality Dashboard) ?
Les outils natifs Microsoft fournissent des métriques précieuses mais présentent deux limites principales pour le diagnostic d’incidents unitaires : une vision présentant généralement une certaine latence (15 à 30 minutes entre l’événement et la disponibilité des données détaillées), et des métriques agrégées par site ou par utilisateur rendant l’analyse d’un appel précis plus complexe. MS Teams Observability complète ces outils en proposant une analyse unitaire en temps quasi-réel de chaque appel via une timeline waterfall par stream, directement intégrée dans Dynatrace. L’approche est complémentaire : les outils Microsoft restent pertinents pour la vue stratégique globale et les tendances à long terme, tandis que l’analyse appel par appel excelle pour le diagnostic opérationnel immédiat des incidents signalés.
Comment passer du mode démo à l’analyse de mes vrais appels Teams en production ?
Le passage en mode production nécessite deux éléments : le déploiement de l’agent MS Teams Observability qui collecte les métriques enrichies via les APIs Microsoft Teams et les envoie dans votre environnement Dynatrace, et l’activation d’une licence Phenisys (ou la souscription à un essai gratuit) pour débloquer les fonctionnalités production. Une fois configuré, vos appels réels, utilisateurs, sites et indicateurs réseau alimentent automatiquement l’application dans Dynatrace, sans modification de votre infrastructure Teams ni déploiement d’agents sur les postes utilisateurs. Le mode démo reste accessible indéfiniment pour les formations d’équipes ou les démonstrations managériales, sans exposer les données sensibles.
Quels sont les prérequis techniques pour utiliser MS Teams Observability en production ?
Trois prérequis principaux structurent le déploiement : un environnement Dynatrace (SaaS ou Managed) avec droits d’installation d’applications depuis le Hub, des accès APIs Microsoft Teams pour la collecte de données (permissions lecture des métriques de qualité d’appels, sans accès au contenu des conversations), et un serveur ou une machine virtuelle pour héberger l’agent de collecte (Windows ou Linux, spécifications techniques modestes). Aucune modification de l’infrastructure Microsoft Teams n’est requise, et aucun agent n’est déployé sur les endpoints utilisateurs. La collecte s’effectue de manière centralisée via les APIs cloud Microsoft, simplifiant considérablement l’architecture par rapport aux solutions nécessitant des sondes distribuées.
L’analyse appel par appel permet-elle vraiment de réduire la dépendance aux experts réseau et Teams ?
Oui, de manière significative sur la phase de diagnostic initial. La timeline waterfall et l’identification automatique des segments réseau ou sites problématiques permettent au support niveau 1 de qualifier précisément l’incident (réseau local, incident Microsoft, problème utilisateur isolé, dégradation subnet spécifique) avant toute escalade. Les experts restent mobilisés sur la résolution effective (intervention sur switch défaillant, optimisation QoS, reconfiguration réseau) mais ne sont plus sollicités systématiquement dès le signalement d’un incident pour en comprendre la nature. Les retours terrain montrent une réduction de 60 à 70% des escalades effectuées uniquement pour diagnostic, sans action de résolution associée.
Les données du mode démo sont-elles représentatives de scénarios réels de production ?
Oui, les données simulées sont conçues pour refléter des situations rencontrées couramment en production : appels dégradés avec causes variées (problème réseau local, incident Microsoft déclaré, utilisateur avec connexion défaillante), sites géographiques présentant des risques identifiés, corrélation avec des incidents Microsoft 365 réels historiques, variabilité de qualité selon les subnets et les plages horaires. L’objectif consiste à permettre une projection réaliste dans vos propres cas d’usage (diagnostic d’incident précis, analyse de site problématique, identification de patterns récurrents) sans nécessiter l’accès à vos données de production. Il s’agit d’un environnement sandbox pédagogique pleinement fonctionnel, pas d’une simple capture d’écran statique.
MS Teams Observability remplace-t-il les outils de monitoring réseau existants ?
Non, l’approche est complémentaire plutôt que substitutive. Les outils de monitoring réseau (analyse de flux, performance WAN, supervision QoS) restent essentiels pour la supervision globale de l’infrastructure. MS Teams Observability apporte une couche spécialisée « expérience utilisateur Teams » avec corrélation appel ↔ réseau que les outils génériques ne fournissent pas nativement. L’avantage de l’intégration Dynatrace réside justement dans la capacité à centraliser dans une plateforme unique l’observabilité applicative (dont Teams), le monitoring réseau, la supervision infrastructure et l’analyse de l’expérience utilisateur finale, évitant la multiplication d’outils silotés nécessitant des corrélations manuelles chronophages lors des incidents.
Votre plan d’action immédiat : 4 actions concrètes pour démarrer dès aujourd’hui.
- Télécharger l’application MS Teams Observability et l’installer dans votre environnement Dynatrace via le Hub (durée totale : moins de 2 minutes)
- Explorer le mode démo en simulant le diagnostic d’un incident précis : rechercher un appel dégradé, afficher sa timeline waterfall, identifier le stream et le segment réseau responsables
- Documenter le temps actuellement consacré au diagnostic d’incidents Teams dans votre organisation (baseline) pour mesurer le gain après adoption
- Identifier les 2-3 incidents Teams récents les plus chronophages et rejouer leur diagnostic dans le mode démo pour visualiser concrètement la différence méthodologique
Plutôt que de conclure sur ce qui a été dit, posez-vous cette question pour la suite de votre projet : si vos équipes support pouvaient autonomiser 70% des diagnostics Teams actuellement escaladés aux experts, quels chantiers stratégiques ces ressources libérées pourraient-elles enfin aborder ?